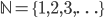Anbei ein kleines Skript, welches ich gerne nutze um auf einer frischen Ubuntu 20.04 Installation Google Kubernetes inkl. dem Dashboard und dem Metis Server zu Testzwecken auszurollen. Das Skript hat keinerlei Vorbedingungen sondern kann direkt nach einer Ubuntu 20.04 (Server-)Installation ausgeführt werden. Wie immer gilt jedoch:
Bitte testet das Skript vorab in einer sicheren Umgebung.
#!/bin/bash
# Lösche die folgende Zeile, wenn du das Skript verstanden und an dein System angepasst hast :)
exit
echo "Update System"
apt-get update
apt-get -y dist-upgrade
echo "Install some tools"
apt-get -y install aptitude apt-transport-https curl nftables net-tools zip jq
echo "Add Kubernetes Repository"
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
echo "deb https://apt.kubernetes.io/ kubernetes-xenial main" > /etc/apt/sources.list.d/kubernetes.list
apt-get update
echo "Install Docker"
apt-get -y install docker.io
systemctl enable docker.service
echo "Install Kubernetes"
apt-get -y install kubelet kubeadm kubectl
echo "Enable IP Forwarding"
sysctl -w net.ipv4.ip_forward=1
echo "net.ipv4.ip_forward = 1" >> /etc/sysctl.conf
echo "Disable SWAP"
cp /etc/fstab /tmp/fstab
echo "" > /etc/fstab
cat /tmp/fstab | grep -v swap >> /etc/fstab
rm /tmp/fstab
swapoff -a
echo "Setup Kubernetes Cluster"
kubeadm config images pull
kubeadm init --pod-network-cidr=192.168.0.0/16 --apiserver-advertise-address=<HIER DIE IP ADRESSE DES SERVERS>
echo "Distribute .kube Files for root"
mkdir -p /root/.kube
cp -i /etc/kubernetes/admin.conf /root/.kube/config
chown root:root /root/.kube/config
echo "Distribute .kube Files for user"
mkdir $HOME/.kube
sudo cp /etc/kubernetes/admin.conf $HOME/.kube/
sudo chown $(id -u):$(id -g) $HOME/.kube/admin.conf
export KUBECONFIG=$HOME/.kube/admin.conf
echo "Untainted Node"
kubectl taint nodes --all node-role.kubernetes.io/master-
echo "Install calico"
kubectl apply -f https://docs.projectcalico.org/manifests/calico.yaml
echo "Install Kubernetes Dashboard"
kubectl create namespace kubernetes-dashboard
mkdir /tmp/certs
openssl genrsa -out /tmp/certs/tls.key 4096
openssl rsa -in /tmp/certs/tls.key -out /tmp/certs/tls.key
openssl req -sha256 -new -key /tmp/certs/tls.key -out /tmp/certs/tls.csr -subj '/CN=localhost'
openssl x509 -req -sha256 -days 365 -in /tmp/certs/tls.csr -signkey /tmp/certs/tls.key -out /tmp/certs/tls.crt
kubectl -n kube-system create secret generic kubernetes-dashboard-certs --from-file=/tmp/certs -n kubernetes-dashboard
rm -r /tmp/certs/
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0-rc7/aio/deploy/recommended.yaml
kubectl apply -f ./install/dashboard-adminuser.yaml
kubectl apply -f ./install/dashboard-role.yaml
kubectl create clusterrolebinding kube-dashboard-binding --clusterrole=admin --user=admin-user
openssl genrsa -out /tmp/kbdb.key 4096
openssl req -config ./install/dashboard-csr.cnf -new -key /tmp/kbdb.key -nodes -out /tmp/kbdb.csr
export BASE64_CSR=$(cat /tmp/kbdb.csr | base64 | tr -d '\n')
cat ./install/dashboard-csr.yaml | envsubst | kubectl apply -f -
kubectl certificate approve mycsr
echo "Install Metis-Server"
wget https://get.helm.sh/helm-v2.16.5-linux-amd64.tar.gz
tar -zxvf helm-v2.16.5-linux-amd64.tar.gz
mv ./linux-amd64/helm /usr/local/bin/helm
rm ./helm-v2.16.5-linux-amd64.tar.gz
rm -r ./linux-amd64
/usr/local/bin/helm init --wait
kubectl create serviceaccount --namespace kube-system tiller
kubectl create clusterrolebinding tiller-cluster-rule --clusterrole=cluster-admin --serviceaccount=kube-system:tiller
kubectl patch deploy --namespace kube-system tiller-deploy -p '{"spec":{"template":{"spec":{"serviceAccount":"tiller"}}}}'
kubectl apply -f ./install/metis.yaml
sleep 10
/usr/local/bin/helm install --name metrics-server stable/metrics-server --namespace metrics --set args={"--kubelet-insecure-tls=true,--kubelet-preferred-address-types=InternalIP\,Hostname\,ExternalIP"}
echo "Generating Access Keys"
sleep 60
kubectl get csr mycsr -o jsonpath='{.status.certificate}' | base64 --decode > /tmp/kbdb.crt
openssl pkcs12 -export -in /tmp/kbdb.crt -inkey /tmp/kbdb.key -out /tmp/kbdb.p12 -passout pass:
mv /tmp/kbdb.p12 $HOME/
chown $(id -u):$(id -g) $HOME/kbdb.p12
rm /tmp/kbdb.key
rm /tmp/kbdb.csr
rm /tmp/kbdb.crt
kubectl -n kubernetes-dashboard describe secret $(kubectl -n kubernetes-dashboard get secret | grep admin-user | awk '{print $1}') > /tmp/token.txt
mv /tmp/token.txt $HOME/
chown $(id -u):$(id -g) $HOME/token.txt
Das zu verwendende Clientzertifikat zum Import für euren lokalen Browser liegt anschließend unter $HOME/kbdb.p12. Der Zugriffstoken liegt unter $HOME/token.txt. Folgende Dateien habe ich im Skript im Unterordner "install" verwendet:
dashboard-adminuser.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
dashboard-csr.cnf
[ req ]
default_bits = 2048
prompt = no
default_md = sha256
distinguished_name = dn
[ dn ]
CN = admin-user
[ v3_ext ]
authorityKeyIdentifier=keyid,issuer:always
basicConstraints=CA:FALSE
keyUsage=keyEncipherment,dataEncipherment
extendedKeyUsage=serverAuth,clientAuth
dashboard-csr.yaml
apiVersion: certificates.k8s.io/v1beta1
kind: CertificateSigningRequest
metadata:
name: mycsr
spec:
groups:
- system:authenticated
request: ${BASE64_CSR}
usages:
- digital signature
- key encipherment
- server auth
- client auth
dashboard-role.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard
metis.yaml
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: kubelet-api-admin
subjects:
- kind: User
name: kubelet-api
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: system:kubelet-api-admin
apiGroup: rbac.authorization.k8s.io
Quellen / Bildnachweis:
- Beitragsbild: © Alex - Fotolia.com