
Die Wichtigkeit der Auswertung von Log-Dateien der Netzwerke-Hardware oder von Servern ist den meisten Administratoren bewusst. In der Praxis ist es jedoch häufig, das sich die Analyse darauf beschränkt, die wichtigsten Protokolldateien der letzten Tage durchzuschauen und die Erreichbarkeit von Services zu prüfen. Durch den Verzicht auf ein effizientes Log-(bzw. Event-)Management werden viele Gelegenheiten verpasst, drohende Systemstörungen oder Ausfälle frühzeitig zu erkennen.
Ich möchte in diesem Beitrag eine Möglichkeit vorstellen, große Protokollmengen mit mehreren Millionen Einträgen systematisch, automatisiert und zeitsparend auswerten zu können. Als Software werde ich hierbei das Open Source Log Management Tool Graylog2 verwenden.
Graylog2 - Dashboards
Teil eines effizienten Log Management Prozesses sind Dashboards, das sind kleine Übersichten mit vordefinierten Auswertungen der Log-Daten. Ein Dashboard für eine DMZ könnte zum Beispiel wie folgt aussehen:
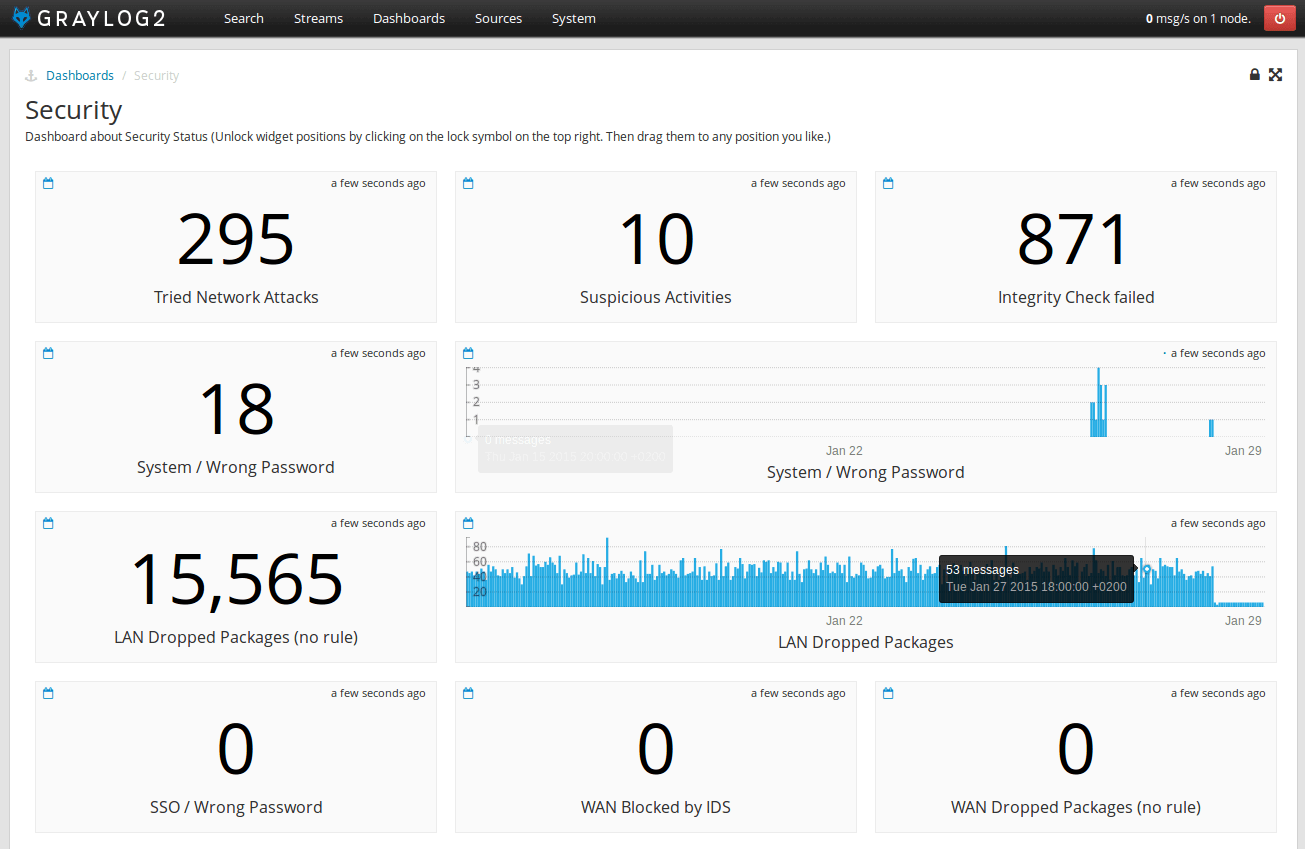
Im Optimalfall werden sämtliche Logmeldungen bereits automatisiert so stark gefiltert und ausgewertet, dass das Dashboard auf einen Blick den Zustand der Infrastruktur visualisiert. Ein Klick auf den Wert des Dashboards zeigt Details zum angezeigten Item.
Ideen zur Umsetzung
Ich möchte kein weiteres Tutorial für die Nutzung und Konfiguration von Graylog2 veröffentlichen, daher im folgenden einige Ideen für die Umsetzung eines zentralen Log Managements:
- Per Default sollten die Meldungen aller Systeme ungefiltert auf dem Log-Server gesammelt werden, dass erleichtert die Analyse später sehr.
- Netzwerk-Hardware, z.B. Cisco Router und Switches bieten die Möglichkeit, z.B. auf Basis von ACLs Meldungen an einen Syslog-Server zu übermitteln. Auch diese Möglichkeiten sollten bedacht werden!
- NTP verwenden: Eine einheitliche Uhrzeit aller Meldungen ist für eine spätere Auswertung sehr wichtig! Alternativ kann Graylog2 so konfiguriert werden, dass es die Uhrzeig der eingehenden Meldungen überschreibt.
- Ein Log-Server stellt eine besonders zu schützende Netzwerkkomponente dar. Werden z.B. primär Syslog-Meldungen über UDP versendet, kann der Server mit Hilfe einer Data-Diode sehr sicher und relativ leicht abgesichert werden.
Prüfung auf Normalverhalten unter Linux
Stark gehärtete Server und Komponenten haben eine Vielzahl an Parametern, die sich nie, oder nur unter bestimmten Umständen ändern. Ein Beispiel hierfür ist die Art und Anzahl der Prozesse, die an einem Netzwerkport auf Anfragen warten. Diese Werte sollten automatisiert und periodisiert geprüft werden, z.B. mit folgendem Skript:
## Check if Application XYZ is running
if [ -z "$(pidof xyz)" ]
then
logger "[MAN CHECK] Application XYZ is not running"
fi
## Check ifconfig line count
lines=$(ifconfig | sed $= -n)
if [ $lines -ne 64 ]
then
logger "[MAN CHECK] Invalid ifconfig line count"
fi
## Check netstat -tulpen
lines=$(netstat -tulpen | sed $= -n)
if [ $lines -ne 4 ]
then
logger "[MAN CHECK] Invalid netstat count"
fi
## Check if SSH is active
netstat -tulpen | grep "ssh" && logger "[MAN CHECK] SSH is running"
Das kurze Skriptbeispiel beinhaltete nur sehr einfache, plakative Beispiele. Dieser Beitrag soll Ideen für eine mögliche Umsetzung liefern. In einer produktiven Umgebungen sollten die Tests deutlich exakter programmiert werden!
Die Beispiele zeigen jedoch gut: Alles was sich über eine Kommandozeile abfragen lässt, kann intervallmäßig geprüft werden.
Auf dem Log-Server lassen sich darauf folgend alle Meldungen filtern und visualisieren, die im Text die Worte [MAN CHECK] haben: Ein Hinweis für den Administrator, dass er hier tätig werden sollte!
Fazit zum Log Management
Ein professionelles Log-Management ist für die Sicherheit und Stabilität einer Infrastruktur mit eine der wichtigsten Komponenten! In der heutigen Zeit gibt es keine Gründe mehr, darauf zu verzichten: Es lässt sich leicht konfigurieren, gut absichern und nach belieben detaillieren.
Auf der Basis ermittelter Normverhaltenswerte lassen sich Anomalien in einer Infrastruktur sehr gut herauslesen. Wird ein solches Tool gut konfiguriert, lässt es sich viel Zeit sparen: Im Optimalfall wird dem Administrator nur noch angezeigt, wenn Handlungsbedarf besteht!
Bildnachweise:
- © Kesu - Fotolia.com